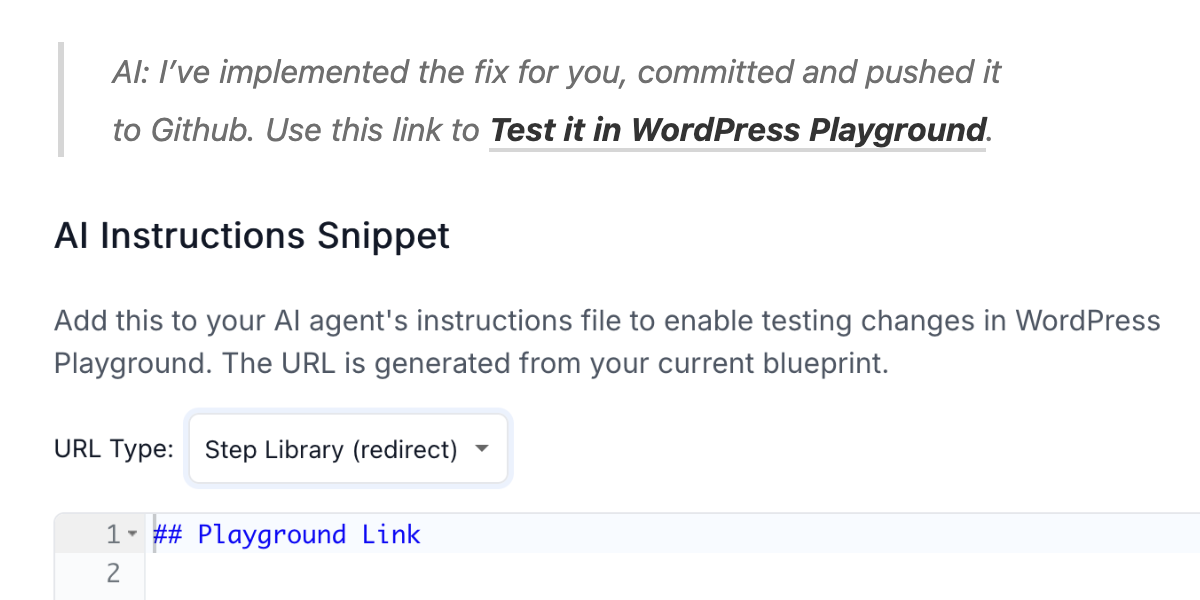
With AI coding assistants and WordPress Playground, you can now develop WordPress plugins from your phone. Here’s how to set it up.
With AI coding assistants and WordPress Playground, you can now develop WordPress plugins from your phone. Here’s how to set it up.

These days you can just fix and adapt incomplete tools that you encounter with AI like Claude Code!