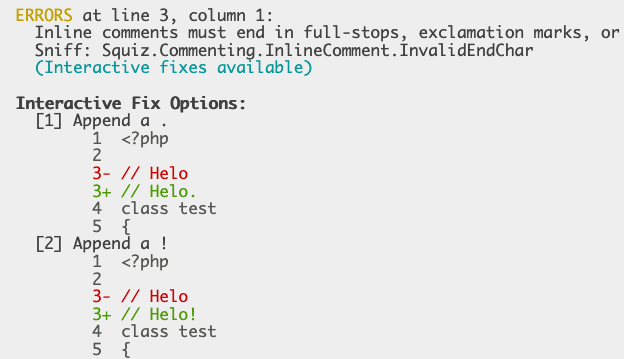
It can be very time consuming to resolve issues detected by PHP Code Sniffer. An interactive mode for phpcbf could make things much faster!
It can be very time consuming to resolve issues detected by PHP Code Sniffer. An interactive mode for phpcbf could make things much faster!
Suppose you have a ressource on the web (for example an API) that either generates a lot of load, or that is prone to be abused by excessive use, you want to rate-limit it. That is, only a certain number of requests is allowed per time-period. A possible way to do this is to use…